InTDS ArchivebyCristian LeoThe Math Behind Fine-Tuning Deep Neural NetworksDive into the techniques to fine-tune Neural Networks, understand their mathematics, build them from scratch, and explore their…Apr 3, 20247Apr 3, 20247
InTDS ArchivebySrijanie Dey, PhDDeep Dive into Transformers by Hand ✍︎Explore the details behind the power of transformersApr 12, 20248Apr 12, 20248
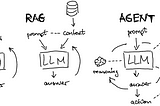
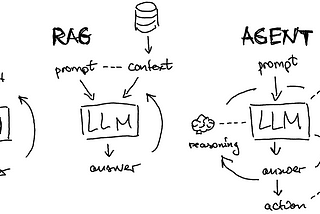
InTDS ArchivebyAlex HoncharIntro to LLM Agents with Langchain: When RAG is Not EnoughFirst-order principles of brain structure for AI assistantsMar 15, 202417Mar 15, 202417
InTDS ArchivebyMariya MansurovaText Embeddings: Comprehensive GuideEvolution, visualisation, and applications of text embeddingsFeb 13, 202421Feb 13, 202421
InTDS ArchivebyBenjamin EtienneA Complete Guide to Write your own TransformersAn end-to-end implementation of a Pytorch Transformer, in which we will cover key concepts such as self-attention, encoders, decoders, and…Feb 24, 202410Feb 24, 202410
InAI AdvancesbyNirmalya GhoshUsing Mixtral 8x7B For NLP Tasks On Small GPUsLarge language models (LLM) are made up of billions of parameters, thus posing challenges when loading them onto GPU memory for model…Jan 1, 20245Jan 1, 20245
InTowards AIbyVaibhawkhemka(New Approach🔥) LLMs + Knowledge Graph : Handling Large documents and data for any industry —…Most of the Real World data replicate Knowledge graph. In this messy world, one will hardly find a linear data of information. AI system…Dec 12, 20231Dec 12, 20231
InTDS ArchivebyIulia BrezeanuHow to Detect Hallucinations in LLMsTeaching Chatbots to Say “I Don’t Know”Dec 31, 202312Dec 31, 202312
InTowards AIbyPatrick MeyerEntity Recognition with LLM: A Complete EvaluationLLMs are capable of performing a wide range of NLP tasks, such as named entity recognition. In this study, I tested an open-source library…Sep 1, 20233Sep 1, 20233
Knowledgator EngineeringAchieve 90% Results in Few-Shot Text Classification with Just 0.1% DataZero-shot abilities of modern LLMs are truly inspiring and make us feel that AGI is pretty close. However, it requires large networks and…Dec 27, 2023Dec 27, 2023
InTDS ArchivebyMina GhashamiByte-Pair Encoding For BeginnersAn illustrative guide to BPE tokenizer in plain simple languageOct 10, 20231Oct 10, 20231
InTDS ArchivebyVyacheslav EfimovLarge Language Models: RoBERTa — A Robustly Optimized BERT ApproachLearn about key techniques used for BERT optimisationSep 24, 2023Sep 24, 2023
InTowards AIbyRodrigo AgundezCosine Similarity for 1 Trillion Pairs of VectorsIntroducing ChunkDotApr 4, 20237Apr 4, 20237
Fanghua (Joshua) YuEfficient Similarity Search & Clustering of Dense Vectors in Neo4jScalable Similarity Search of GPT-3 Text EmbeddingsFeb 26, 20232Feb 26, 20232
Pierre GuillouDocument AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet datasetPost about training a Document Understanding model on DocLayNet, and also its finetuning and inference code via 2 notebooks.Feb 10, 2023Feb 10, 2023
InDev GeniusbySung KimHow to Get Around OpenAI GPT-3 Token LimitsPython Developer’s Guide to OpenAI GPT-3 APIFeb 6, 20233Feb 6, 20233
InTowards AIbySergi Castella i SapéTrends in AI — 2023 Round-upWhat’s next for Language Models, Reinforcement Learning, Computer Vision, and leading AI companies like OpenAI and Google?Jan 25, 20231Jan 25, 20231
Olasimbo ArigbabuFine-tuning OpenAI GPT-3 to build Custom ChatbotIntroductionJan 25, 2023Jan 25, 2023
Cerebras SystemsContext is Everything: Why Maximum Sequence Length Matters for AIGPU-Impossible™ sequence lengths on Cerebras systems may enable breakthroughs in Natural Language Understanding, drug discovery and…Aug 17, 20222Aug 17, 20222
InTDS ArchivebyAyoola OlafenwaThe Concept of Transformers and Training A Transformers ModelStep by step guide on how transformer networks workOct 28, 2022Oct 28, 2022