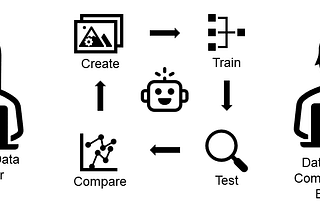
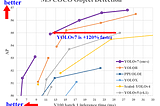Megagon LabsHybrid Active Learning for Low-Resource LM Fine-tuningWe identified two key designs that can improve the effectiveness and efficiency of sample acquisition.Feb 21, 2023Feb 21, 2023
InTowards AIbyChinmay BhaleraoImproving Accuracy of Text Extraction with Simple Techniquesunderstanding data and problem statements to make predictions betterFeb 14, 20234Feb 14, 20234
InTDS ArchivebyBex T.5 Best Python Synthetic Data Generators And How to Use Them When You Lack DataLet's get even more dataJan 23, 20231Jan 23, 20231
InTowards AIbySergi Castella i SapéTrends in AI — 2023 Round-upWhat’s next for Language Models, Reinforcement Learning, Computer Vision, and leading AI companies like OpenAI and Google?Jan 25, 20231Jan 25, 20231
Chinmay BhaleraoComprehensive Guide: Top Computer Vision Resources All in One BlogSave this blog for comprehensive resources for computer visionJan 27, 20234Jan 27, 20234
InTowards AIbyChinmay BhaleraoWorking on a Computer Vision project? These code chunks will help you !!!An introduction to a few “used to” methods in a computer vision projectNov 27, 20221Nov 27, 20221
InML6teambyMathias LeysThe Art of Pooling Embeddings 🎨In this blogpost we will discover the complexity of pooling that hides behind its apparent simplicity.Jun 20, 20222Jun 20, 20222
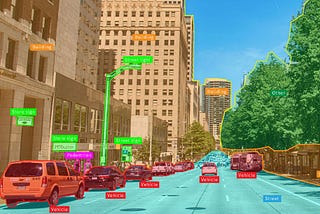
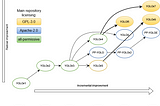
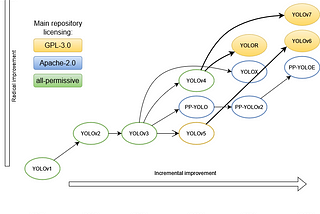
InDeelvin Machine LearningbyMaxim IvanovThe evolution of the YOLO neural networks family from v1 to v7.In the previous parts (part 1, part 2) of the article, we reviewed the first 9 architectures of the YOLO family. In this final article, we…Nov 14, 20221Nov 14, 20221
Stanislau BeliasauHow to fine tune VERY large model if it doesn’t fit on your GPUMemory-efficient techniques to defeat the problem of “CUDA memory error..” during trainingApr 11, 20222Apr 11, 20222
InVirtusLabbyPaweł PęczekComputer Vision in production –Nvidia DeepStreamWe examine Nvidia DeepStream, an emerging solution for implementing computer vision within your software projects.Jan 28, 20223Jan 28, 20223
InML SummariesbyGowthami SomepalliWhen Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations —…Paper: When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations Link…Feb 21, 20221Feb 21, 20221
Sik-Ho TsangReview — PVTv2: Improved Baselines with Pyramid Vision TransformerOutperforms PVT/PVTv1, Swin Transformer, TwinsJul 7, 2022Jul 7, 2022
InTowards DevbyAmalYOLOv7 now Outperforms All Known Object Detectors!YOLOv7 has now surpassed all of the known object detectors like YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR…Jul 13, 20224Jul 13, 20224
Sik-Ho TsangReview — DINO: Emerging Properties in Self-Supervised Vision TransformersDINO, A Form of Self-Distillation with No LabelsJun 14, 2022Jun 14, 2022
InRenderedAIbyChris AndrewsAI Job of the Future: Synthetic Data EngineerWe don’t teach data scientists about 3D Graphics — and we shouldn’t. The skillset required to create synthetic datasets fundamentally…Apr 15, 20225Apr 15, 20225
yanis labrakHow to Train a Custom Vision Transformer (ViT) Image Classifier to Help Endoscopists in under 5 minMake your own Image Classifier for the healthcare industry in less than 5 min with HuggingFace and HugsVision.Sep 2, 20213Sep 2, 20213
Sik-Ho TsangReview — What Makes Instance Discrimination Good for Transfer Learning?Exemplar-v1 & Exemplar-v2, Supervised Contrastive LearningJul 10, 2022Jul 10, 2022
Revca - Helping Companies achieve AI completenessYOLOv6 : Explanation, Features and ImplementationYOLOv6 is a recent addition to the long line of state-of-the-art object detection YOLO models, which has shown quite a decent performance…Jun 29, 2022Jun 29, 2022
InDataSeriesbyJesus RodriguezDeepMind and OpenAI Ideas to Incorporate Human Feedback in Reinforcement Learning AgentsA paper from two years ago introduces some clever ideas to fine tune reward functions in reinforcement learning agents.Jan 4, 2022Jan 4, 2022